

In unserer großen Übersicht zu Künstlicher Intelligenz haben wir das Thema Deep Learning bereits angerissen. Es handelt sich dabei um eine Methode, eine Künstliche Intelligenz zu trainieren. Dabei bildet sie vereinfacht die Funktionsweise des menschlichen Gehirns nach. In diesem Artikel gehen wir deutlich mehr in die Tiefe, wie Deep Learning die menschliche Informationsverarbeitung adaptiert und wo Deep Learning überhaupt zum Einsatz kommt. Aber keine Angst – wir werden auch nicht zu wissenschaftlich.
Wie verarbeitet der Mensch Informationen?
Wenn wir etwas sehen, werden eine ganze Menge Informationen verarbeitet. Wir erkennen Menschen, ihre Gesichter, können in der Mimik auf den Gemütszustand schließen. Die Kleidung gibt uns Aufschluss auf Herkunft, Szene-Zugehörigkeit oder besondere Aufgabe, etwa durch eine Uniform. Es ist das Ergebnis unserer Erfahrung. Unser Gehirn verarbeitet ständig Informationen und wertet sie neu aus. Liegt unsere Einschätzung öfter daneben, ändert sich die Gewichtung, mit denen wir bestimmte Merkmale beachten.
Das alles funktioniert über ein neuronales Netz. Informationen, etwa durch Sehen, Tasten, Hören oder Riechen werden dabei an Nervenzellen, auch Neuronen genannt, weitergegeben. Ab einer gewissen Summe dieser Eingangssignale feuert das Neuron selbst ein elektrisches Signal an weitere Neuronen. Wir haben Milliarden dieser Neuronen, die über die sogenannten Synapsen miteinander verbunden sind. Dieses riesige Netz an miteinander verbundenen Neuronen macht es erst möglich, dass wir so viele Dinge unterscheiden.
Das menschliche Gehirn ordnet dabei gelernten Mustern an Informationen Bedeutungen oder Körperreaktionen zu. Dabei lernt es ständig dazu. Je öfter eine Synapse genutzt wird, desto stärker werden die Signale. Auch bilden sich gegebenenfalls neue Synapsen zwischen Neuronen. Dadurch werden wir besser in Bereichen, mit denen wir uns viel beschäftigen. Durch ein bewusstes Training des Gehirns können wir das Entwickeln neuer Synapsen fördern und damit unsere kognitiven Fähigkeiten erhöhen.
Wozu maschinelles Lernen? Wozu Deep Learning?
Auf dem ersten Blick ist ein Computerprogramm auch der menschlichen Informationsverarbeitung ähnlich. Das Programm erhält Informationen, verarbeitet diese und gibt ein Ergebnis aus. Die Funktionsweise ist jedoch viel statischer. Der Programmierer gibt vor, welche Informationen auf welche Art verarbeitet werden. Die gleichen Informationen führen also zu den immer gleichen Ergebnissen. Es ändert sich nichts an der Gewichtung der Informationen.
Das ist praktisch für Aufgaben, die nach einfachen und festen Regeln funktionieren. Das Interpretieren einer Handschrift überfordert ein klassisches Programm jedoch bereits schnell. Klassische Programme sind dabei auf saubere Druckschrift angewiesen, die man mit festen Regeln beschreiben kann. Die meisten Handschriften sind allerdings Mischungen aus Hand- und Druckschrift, gelegentlich etwas schludrig und mit unterschiedlichen Übergängen zwischen bestimmten Buchstaben.
Maschinelles Lernen erlaubt es einer Künstlichen Intelligenz, sich durch eine Vielzahl an Daten zu trainieren und wie das menschliche Gehirn wiederkehrende Muster an Daten zu identifizieren. Deep Learning simuliert dabei das menschliche Gehirn in einer sehr vereinfachten Form.
So funktioniert Deep Learning
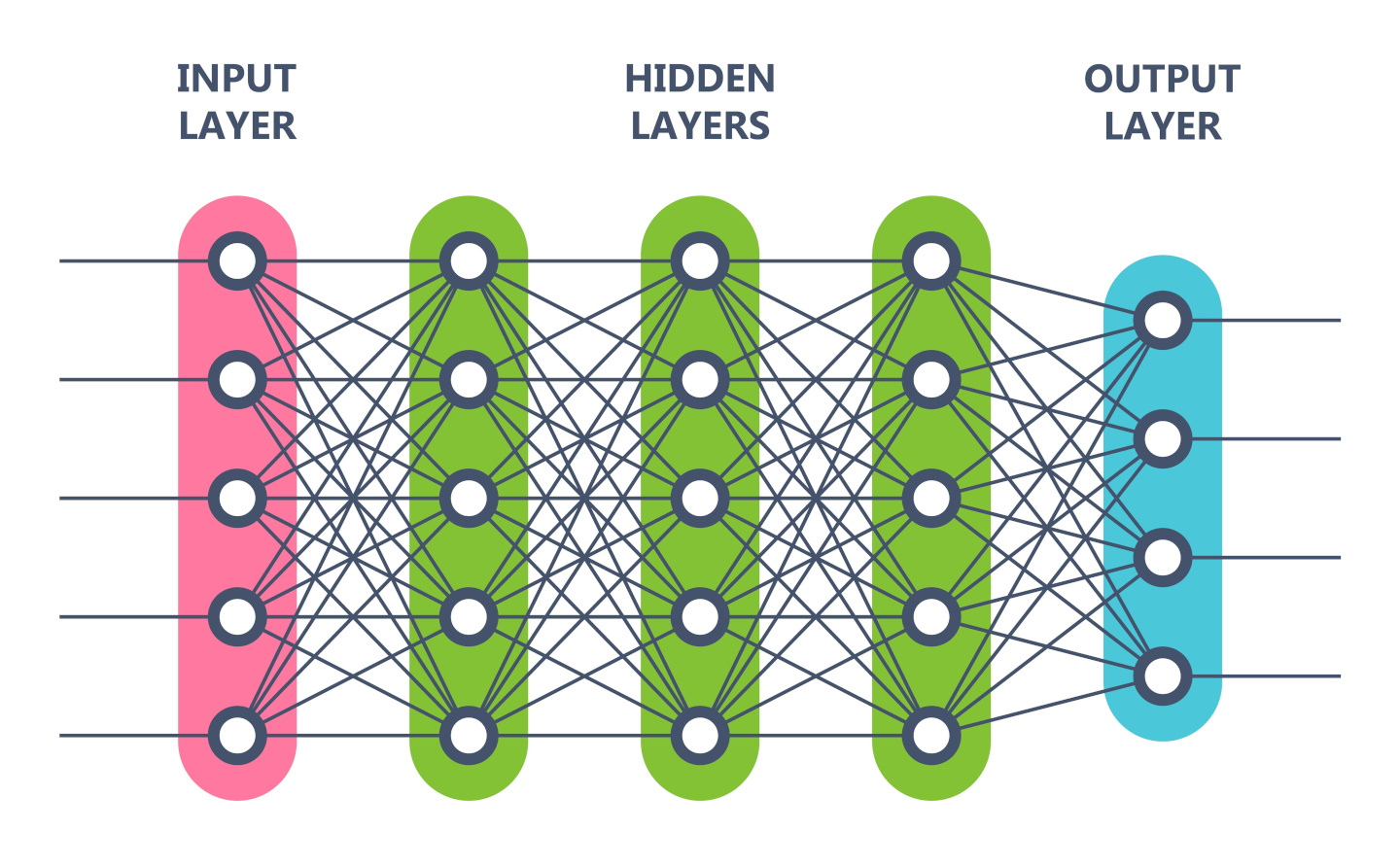
Doch wie funktioniert Deep Learning genau? Im Grunde simuliert Deep Learning die Neuronen des Gehirns. Dieses künstliche neuronale Netz besteht aus mehreren Schichten. Dazu gehört eine Eingangsschicht und eine Ausgabeschicht.
In der Eingabeschicht werden die Neuronen mit Informationen von außen versorgt und geben die Daten, mit einer je nach Neuron unterschiedlichen Gewichtung an die nächste Schicht weiter. Die Eingabe kann im Falle von geschriebenen Buchstaben der Helligkeitswert eines jeden Pixels sein.
Die Ausgabeschicht ist die letzte Schicht, weshalb man auch von Output-Neuronen spricht. Diese bestimmen das Ergebnis der Informationsauswertung. Beim Beispiel der Buchstaben könnte jedes Ausgabe-Neuron für einen Buchstaben stehen. Der berechnete Wert des Neurons steht nicht mehr für den Helligkeitswert, sondern für die Wahrscheinlichkeit, dass es der jeweilige Buchstabe ist. Das Neuron der Ausgabeschicht mit dem höchsten Wert bestimmt die Ausgabe.
Zwischen der Eingangsschicht und Ausgabeschicht gibt es noch eine beliebige Anzahl verborgener Schichten. Dessen Neuronen erhalten ihre Informationen aus den Neuronen der vorherigen Schicht.
Blackbox – Keine Ahnung, was das Programm macht
Klassische Computerprogramme sind abhängig von ihrer Programmierung. Sie verarbeiten Informationen genau so – und nur genau so – wie es ihr Code vorgibt. Es muss also einen Menschen geben, der selbst versteht, wie das Problem gelöst wird und diese Lösung automatisiert. Es muss auch einen Mensch geben, der Tests entwirft, um auszuschließen, dass es Fälle gibt, in denen das Programm nicht richtig funktioniert.
Beim Deep Learning funktioniert das anders. Der Mensch bestimmt die Informationen, mit denen das neuronale Netzwerk gefüttert wird und belehrt das Netzwerk gegebenenfalls, ob das vermutete Ergebnis richtig oder falsch ist. Er hat Kontakt mit der Eingangs- und der Ausgangsschicht. Was jedoch in den verborgenen Schichten dazwischen passiert, ist wie eine große Black Box.
Im Lernprozess verändert sich die Gewichtung, die Neuronen ihren Eingangssignalen zuordnen. In simplen neuronalen Netzwerken lässt sich noch in etwa erahnen, welche Muster die Neuronen herausfinden wollen. Je mehr Schichten und je mehr Neuronen eine Schicht besitzt, desto vielfältiger werden jedoch die Möglichkeiten.
Ab einer gewissen Komplexität des künstlichen neuronalen Netzes lässt sich nicht mehr nachzuvollziehen, was intern überhaupt passiert. Es ist im Prinzip eine mathematische Funktion mit Tausenden oder Millionen variablen Werte. Wie bei unserem Gehirn spielen zu viele Faktoren mit rein, als das wir sie alle benennen können.
Auch Deep Learning ist noch eingeschränkt
Jetzt mag man meinen, dass Künstliche Intelligenz dank Deep Learning mit der Leistung unseres Gehirns konkurriert. Ganz so einfach ist das nicht. Zum einen ist ein künstliches neuronales Netz nicht annähernd so komplex wie das neuronale Netz des Gehirns. Zum anderen ist Deep Learning aber auch für Eingabe und Ausgabe davon abhängig, das wir ihn an Informationen geben und welche Informationen wir erhalten wollen. Wir müssen der Künstlichen Intelligenz viele Daten zum Anlernen geben und ihr gleichsam auch immer wieder Feedback geben.
Außerdem trainiert sich das neuronale Netz auf ein bestimmtes Anwendungsgebiet. Trainieren wir eine KI zur Analyse von Röntenbildern, würde sie versuchen, aus Landschaftbildern plötzlich medizinische Befunde nach den ihr bekannten Mustern abzuleiten. Zugleich sorgen die thematisch nicht passenden Bilder womöglich dafür, dass sie daraufhin ihre Bewertung anpasst und nicht mehr ganz so gut für Röntenbilder funktioniert. Trotz Deep Learnings beschränken sich Künstliche Intelligenzen auf kleine Aufgaben, in denen sie jedoch Muster erkennt, die der menschlichen Wahrnehmung oft verborgen bleiben.
Generative Adversarial Networks
Übersetzt bedeutet Generative Adversarial Networks (GAN) „erzeugende generische Netzwerke“. Wie der Name es schon andeutet, dienen diese Netzwerke dem Erzeugen von Daten, etwa Bildern, die es bis dahin noch nicht gibt, aber der Realität nachempfunden sind. Ein sehr bekanntes Beispiel ist die Seite „This Person Does Not Exist“. Die dort generierten Bilder sind Fotos von Personen, die zwar zum Großteil täuschend echt aussehen, aber tatsächlich nicht existieren. Manchmal entstehen deutliche Abweichungen wie eine dritte Augenbraue, aber die meisten dieser Fotos würde man ohne Wissen nicht als künstlich erachten.
Bei einem GAN fehlt übrigens der Mensch als überwachende Komponente. Stattdessen arbeiten gleich zwei Künstliche neuronale Netze zusammen. Das erste Netz trainiert sich darauf, echte und künstliche Bilder von Personen voneinander zu unterscheiden. Um das zu lernen, bekommt es sowohl echte Fotos, als auch Bilder, die das zweite neuronale Netz erstellt. Dieses trainiert sich nämlich darauf Bilder zu erstellen, die nicht von einem echten Foto zu unterscheiden sind.
Das erste neuronale Netz wird immer besser darin Unterschiede zwischen echten und falschen Bildern zu erkennen. Dadurch fordert es das andere Netz, besser zu werden, um den Test trotzdem zu bestehen. Die beiden Netze trainieren sich also gegenseitig, indem sie immer versuchen, besser zu sein als der Gegenpart.


Beispiele für Einsatz von Deep Learning
KI-Supersampling für Grafikkarten
Deep Learning ist auf dem Markt der Grafikkarten eine neue Wunderwaffe. Nvidia hat eine Künstliche Intelligenz mit Deep Learning angelernt, wie ein hochauflösendes Bild zu einem dazugehörigen schlechter aufgelösten Bild auszusehen hat. Das ganze nennt sich dann DLSS (Deep Learning Super Sampling). Unterstützende Spiele ermöglichen es, in einer niedrigeren Auflösung zu spielen und sich die Auflösung durch die KI hochrechnen zu lassen. Die Grafik sieht dabei weitgehend aus, als wenn das Spiel nativ in der höheren Auflösung läuft. Das Spiel läuft allerdings durch die Berechnungen in niedrigerer Auflösung deutlich flotter.
Unterstützt wird das Feature allerdings nur von den neuen RTX-Grafikkarten, die sogenannte Tensor-Cores verbaut haben. Die Tensor Cores sind Recheneinheiten, die auf Matrixmanipulationen optimiert sind. Das sind Rechenoperationen, die für das Deep Learning besonders wichtig sind. Zwar arbeitet Konkurrent AMD auch bereits an einem ähnlichen Feature, doch Nvidia dürfte dank der Tensor-Kerne einen Performance-Vorteil genießen und hat zudem auch einen zeitlichen Vorsprung.
Deep Learning für Autonomes Fahren
Die Automatisierung von Schienenfahrzeugen ist eine vergleichsweise einfache Angelegenheit. Die Strecken verlaufen in der Regel unabhängig anderer Verkehrsteilnehmer und der Zug bewegt sich nur vorwärts oder rückwärts.
Ganz anders sieht das im Straßenverkehr aus. Ein selbstfahrendes Auto kann sich frei in alle Richtungen bewegen, muss auf Ampeln, Straßenschilder und Verkehrsregeln achten und ist nicht so vernetzt, wie ein in sich abgeschlossenes Zugsystem, wo alle Fahrzeuge einfach miteinander kommunizieren. Darüber hinaus teilen sich Autos ihren Verkehrsraum mit vielen weiteren Autos, Fahrrädern und Fußgänger, deren Wege sich oft kreuzen und die mal mehr mal weniger auf Regeln achten. Dazu kommt eine sehr wechselnde Qualität des Untergrundes, der auch stark vom Wetter beeinflusst wird.
Kurzum: Es gibt viel zu viele Einflüsse, um das Fahrzeug mit einfacher Programmierung sicher durch den Straßenverkehr zu bringen. Autonome Fahrzeuge müssen angelernt werden, um die Verkehrssituation in jedem Moment richtig einzuschätzen und mit Straßenverhältnissen zurecht zu kommen.
Deep Learning in Sicherheitssystemen
Auch in Sicherheitssystemen bietet Deep Learning große Potentiale. Das gilt sowohl für visuelle, als auch digitale Überwachung.
Kamerasysteme können beispielsweise darauf trainiert werden, auffälliges Verhalten zu erkennen. Damit ließen sich sensible Orte wie Flughäfen oder auch Großereignisse wie Olympische Spiele überwachen. Die KI wird dabei mit Videomaterial vom normalen Flughafen oder Stadionbetrieb angelernt, um ungewohnte Verhaltensmuster zu erkennen. Diese könnten dann von einem zuständigen Sicherheitsarbeiter gesichtet werden.
Auch vor digitalen Angriffen kann eine künstliche Intelligenz durch Deep Learning schützen. So überwacht eine Künstliche Intelligenz Datenströme oder im Falle von Banken auch Finanzströme. Angelernt durch anonymisierte Daten ist die KI sensibilisiert, auffällige Vorgänge zu melden.
Image by peshkova via Adobe Stock
Related Articles



Artikel per E-Mail verschicken
Schlagwörter: Künstliche Intelligenz, programmierung